Explainable Radiologist-Aligned VLM for CT Image Quality Assessment
Hi, I'm Jiajun Wang, a researcher focusing on the application of cutting-edge AI in engineering. This blog is my digital garden.
Authors: Jiajun Wang, Yipeng Sun, Siming Bayer, Andreas Maier
Affiliation: Pattern Recognition Lab, Friedrich-Alexander Universität Erlangen-Nürnberg, Germany
Links: GitHub Repository
📖 Abstract
The assessment of computed tomography (CT) image quality has traditionally relied on manual evaluation by radiologists—a method that is both subjective and time-consuming. While Deep Learning methods exist, they often only give quantitative scores and lack explainability. To address this, we propose a parameter-efficient supervised fine-tuning (SFT) framework for the medical VLM, MedGemma-4B-IT. By employing Quantized Low-Rank Adaptation (QLoRA), we aligned the model's visual perception with expert quantitative judgment.
Our results demonstrate a substantial improvement in correlation with expert scores (SRCC=0.7950, PLCC=0.7907) , significantly outperforming zero-shot baselines like Gemini 2.5 Pro and Gemini 2.5 Flash. Most importantly, our model generates professional textual explanations that emulate the reasoning and explanation style of radiologists.
💡 Motivation: Why Explainable AI for CT?
Diagnostic utility in CT scans depends critically on image quality. Degradation due to noise, artifacts, or insufficient contrast can lead to misdiagnoses and repeated examinations.
The Problem with Manual Scoring: It is labor-intensive, time-consuming, and prone to inter-observer variability.
The Problem with Previous AI: Conventional Deep Learning methods (NR-IQA) provide a score but remain opaque, making it difficult to interpret why specific scores are assigned.
The Problem with Cloud VLMs: General-purpose, closed-source VLMs are often constrained by patient privacy regulations.
Our goal was to create a locally deployable, privacy-preserving, and explainable solution.
🛠️ Methodology: The Framework
We formulated CT-IQA (Image Quality Assessment) as a multimodal reasoning task.
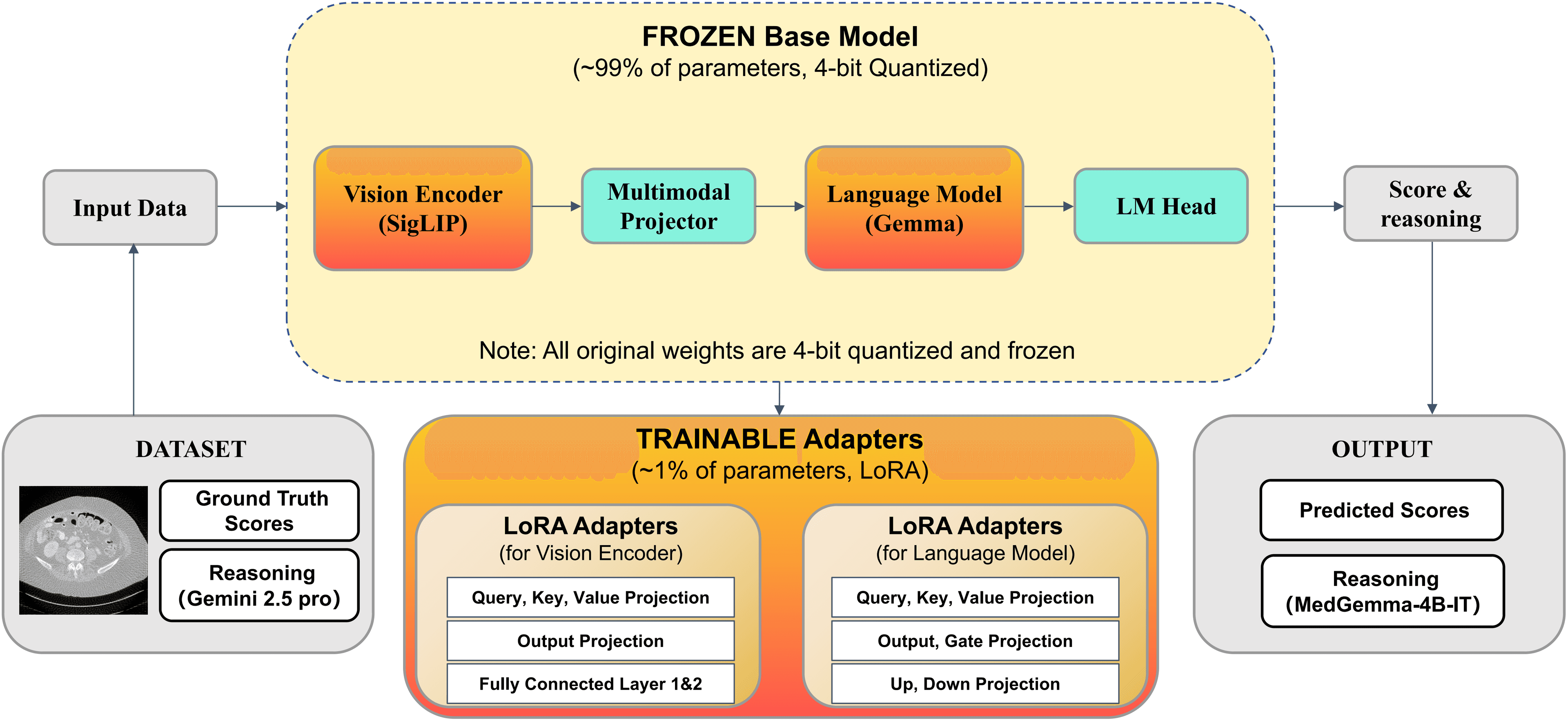
1. The Model Architecture
We selected MedGemma-4B-IT as our base model due to its strong medical priors. The architecture consists of:
Vision Encoder: SigLIP, to capture local anatomical and noise patterns.
Multimodal Projector: Aligns visual representations with the language space.
Language Model: Gemma, generating both the textual reasoning and the final quality scores.

2. Parameter-Efficient Fine-Tuning (QLoRA)
To make training efficient, we used QLoRA.
4-bit Quantization: The backbone weights are quantized to 4-bit precision and frozen to reduce memory consumption.
Trainable Adapters: Only the low-rank adapters (~1% of parameters) are trainable.
3. Data Construction with "Teacher" Distillation
Since large labeled datasets with explanations are scarce, we created a novel pipeline using the LDCTIQA dataset (1,000 CT slices):
Teacher Model: We employed Gemini 2.5 Pro (the best zero-shot performer) to generate expert-level textual explanations for the training data.
Fine-tuning: We trained our model to mimic these high-quality explanations, pairing them with radiologist scores.
📊 Results
Quantitative Performance
Our fine-tuned model achieved state-of-the-art results compared to zero-shot baselines on the test set.
| Model | SRCC (Correlation) | PLCC (Linearity) | MAE (Error) |
|---|---|---|---|
| MedGemma-4B-IT (Fine-tuned) | 0.7950 | 0.7907 | 0.5780 |
| Gemini 2.5 Pro (Zero-shot) | 0.7328 | 0.7204 | 0.6540 |
| Gemini 2.5 Flash (Zero-shot) | 0.7170 | 0.6946 | 0.7360 |
| MedGemma-4B-IT (Zero-shot) | -0.2438 | -0.2029 | 1.4790 |
Data Source: Table 1 in Paper
The fine-tuning improved the SRCC by over +1.0 compared to the original weights.
Qualitative Analysis (Case Study)
In testing, when presented with a low-quality image (Ground Truth Score: 1.2), the zero-shot baseline incorrectly rated it as high quality (3.2).

Our Fine-Tuned Model:
Predicted Score: 1.0 (Very close to GT 1.2).
Generated Reasoning: Correctly identified "Severe Artifacts," "Streak Artifacts," and "High Noise". It explicitly noted that streaks were radiating from the pelvic girdle, obscuring tissue texture.
🚀 Conclusion
We demonstrated that a specialized medical VLM can be fine-tuned to emulate the reasoning style of radiologists. This provides a locally deployable, privacy-preserving, and explainable tool for automated CT image quality assessment.
🔗 Resources
- Code: GitHub - VLM-CT-IQA
📝 Citation
If you find this work helpful, please consider citing our paper:
@inproceedings{wang2025explainable,
title={Explainable Radiologist-Aligned VLM for CT Image Quality Assessment},
author={Wang, Jiajun and Sun, Yipeng and Bayer, Siming and Maier, Andreas},
booktitle={German Conference on Medical Image Computing (BVM)},
year={2026}
}