DSS-SQA: Decoupling Structure and Semantics for Semantic Quality Assessment
Hi, I'm Jiajun Wang, a researcher focusing on the application of cutting-edge AI in engineering. This blog is my digital garden.
Links: GitHub Repository | LoViF 2026 Challenge

As Generative AI (AIGC) fundamentally transforms low-level vision tasks, the way we evaluate image quality is undergoing a massive paradigm shift. In modern generative models, the most pressing issue is no longer just blur or noise, but AIGC semantic hallucinations.
To address this, our team (DSS-SQA: Jiajun Wang, Yipeng Sun, Kaiwei Lian) participated in the LoViF 2026 Challenge on Semantic Quality Assessment. We proposed a novel Full-Reference Image Quality Assessment (FR-IQA) framework that explicitly decouples structural fidelity from semantic alignment.
Our method achieved highly competitive results: a Final Score of 0.8469 on the official test phase and 0.9121 on the validation phase, significantly outperforming traditional metrics, deep-feature metrics (LPIPS, DISTS), and even zero-shot large Vision-Language Models (GPT-5.4, Gemini 3.1 Pro).
🛑 The Challenge: "Shortcut Learning" in Semantic IQA
The LoViF 2026 challenge provides a highly timely and critical benchmark. However, modeling this high-level semantic alignment presents significant obstacles.
The extreme scarcity of training data (only 510 pairs) makes deep neural networks highly prone to "shortcut learning". Instead of learning to evaluate semantic alignment, models easily degenerate into evaluating absolute image sharpness. For instance, a model might erroneously predict a high score for a visually pristine but semantically completely unrelated generated image.
Explicit gating constraints and self-supervised structural priors were vital to overcoming this bottleneck.
🧠 Our Solution: The DSS-SQA Architecture
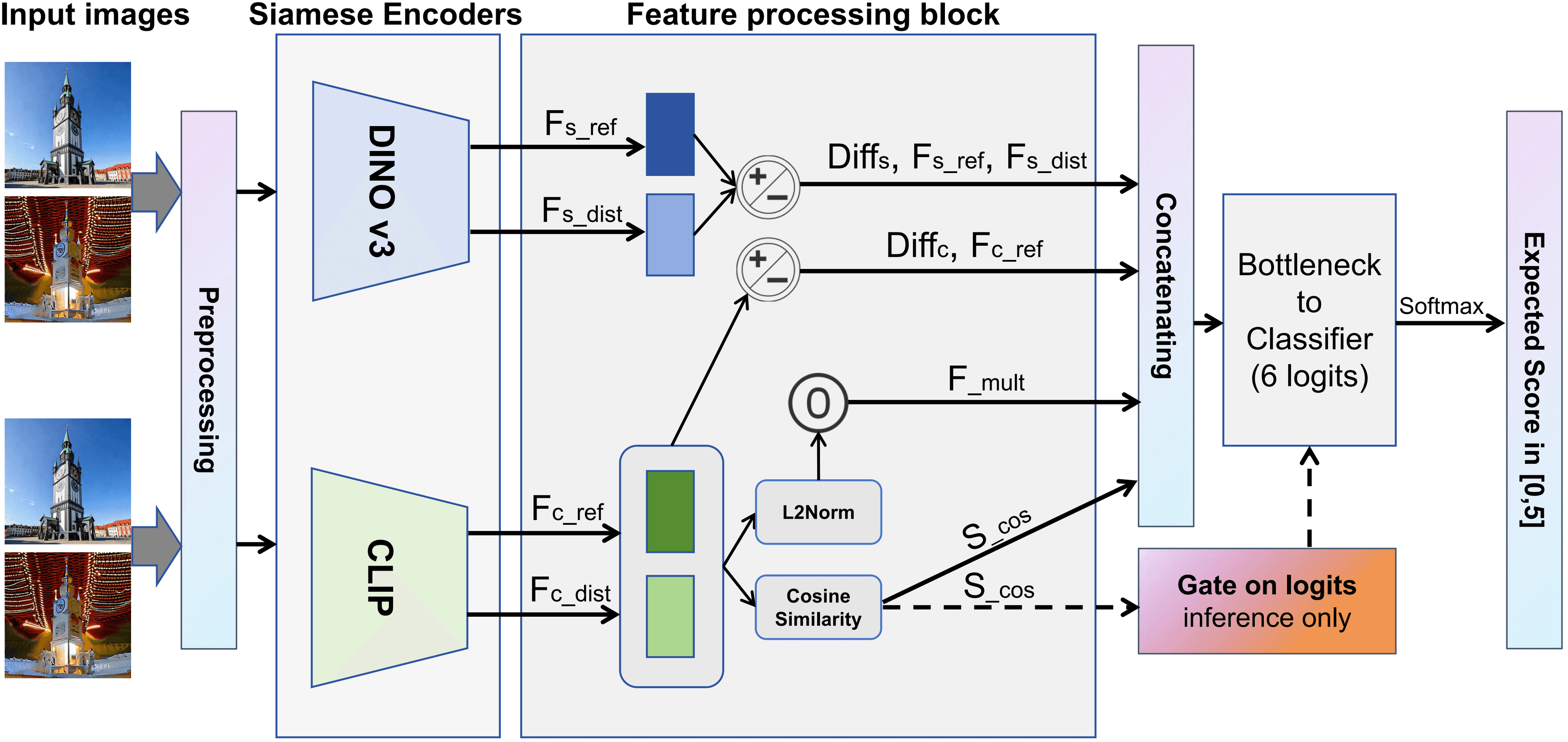
Our proposed solution, DSS-SQA, explicitly decouples structural degradation from semantic hallucinations using a dual-vision backbone (DINOv3 and CLIP).

1. Dual-Vision Siamese Encoders
Recognizing that structure and semantics are orthogonal dimensions, we employ two distinct, frozen pre-trained foundation models:
Structural Awareness (DINOv3): We utilize the DINOv3-Base vision transformer to extract structure-aware global representations (implemented with the DINOv3 CLS token by default, with patch-token fallback only when needed).
Semantic Awareness (CLIP): We employ the CLIP-ViT-L/14 vision encoder to extract global, human-aligned semantic embeddings.
2. Element-wise Multiplication Fusion
To fuse these features, we compute the absolute differences for both branches (\(Diff_{s}\) and \(Diff_{c}\)). Crucially, we introduce an Element-wise Multiplication Fusion for the CLIP features. $$ $$
By default, we apply \(L_{2}\) normalization before the Hadamard product:
mult_clip\(=L_{2}(F_{c_ref}) \odot L_{2}(F_{c_dist})\).We then replace the raw distorted semantic feature with this multiplication result to force the network to rely on fine-grained semantic interaction.
The scalar cosine similarity \(S_{cos}\) is also explicitly injected into the concatenated feature vector.
3. Explicit Semantic Gating Mechanism
To directly combat shortcut learning, we designed an explicit semantic gate. During inference (model.eval()) with semantic gating enabled, if the cosine similarity \(S_{cos}\) falls below a threshold (0.4), the gate applies a hard veto by forcefully pushing the predicted logits toward the lowest quality class (Class 0). This ensures the final expected score approaches zero, effectively penalizing visually pleasing but semantically completely hallucinated pairs.
4. Robust Ensemble Strategy
To maximize robustness and prevent overfitting on the extremely small dataset, we utilized a 5-fold stratified cross-validation strategy during training. During the final testing/inference phase, the expected quality scores from all 5 trained models are averaged (Mean Ensemble) to produce the highly stable final output.
📊 Experimental Results
LoViF 2026 Validation Set
Our method significantly outperforms all baseline metrics, proving that decoupling structure and semantics is highly effective in AIGC evaluation.
| Method | SROCC \(\uparrow\) | PLCC \(\uparrow\) | Final Score \(\uparrow\) |
|---|---|---|---|
| LPIPS (VGG) | 0.7602 | 0.7389 | 0.7516 |
| DISTS | 0.8172 | 0.8055 | 0.8125 |
| GPT-5.4 | 0.7861 | 0.7957 | 0.7900 |
| Gemini 3.1 Pro | 0.8068 | 0.8174 | 0.8110 |
| DSS-SQA (Ours) | 0.9062 | 0.9209 | 0.9121 |
The Final Score is calculated as \(0.6 \times SROCC + 0.4 \times PLCC\). On the official blind test phase, our model achieved a Final Score of 0.8469.
Zero-Shot Generalization on BAPPS
To demonstrate that our model learns universally applicable quality representations rather than overfitting the small LoViF dataset, we conducted zero-shot evaluations on the BAPPS perceptual dataset.
| Method | Trad | CNN | Superres | Overall |
|---|---|---|---|---|
| Human (Ceiling) | 80.8% | 84.4% | 73.4% | 73.9% |
| LPIPS (VGG) | 71.4% | 81.4% | 69.0% | 66.8% |
| DSS-SQA (Ours) | 73.9% | 79.6% | 65.5% | 65.0% |
Despite being optimized for high-level semantic quality, DSS-SQA remains highly competitive with metrics explicitly trained on BAPPS (like LPIPS), proving that our dense DINOv3 representations robustly capture low-level generative artifacts.
💻 Code & Resources
We have open-sourced the complete training and inference pipeline.
- GitHub Repository: atJesse/SIQAv3
If you find our work helpful for your research, feel free to drop a star on GitHub! 🌟